Cuántos problemas hay, que por aparentemente muy conocidos, son susceptibles de poder resolverse mejor y darnos un respiro en vez de proporcionarnos dolores de cabeza. Aquellas técnicas de investigación de mercados que hemos utilizado tantas veces y tantos buenos resultados nos han dado que nuestro propio hábito nos lleva a seguir utilizándolas.
Tal es el caso de algunas de ellas, o de sus problemas añadidos, que nos gustaría tratar en este artículo, como por ejemplo:
• Los problemas de segmentación (que tanto apasionan al sector farmacéutico).
• La realización de múltiples estudios con escalas de puntuación, Likert, o similares.
• El estudio de las preferencias.
• Los estudios de pérdidas y ganancias de pacientes, si variamos determinados atributos.
• Los mapas de percepción en los que se nos escapan las preferencias, que a veces implícitamente consideramos.
Estos y muchos otros, son problemas que pueden tratarse de mejor forma que la habitual y sobre todo darnos resultados más realistas y fiables.
Los problemas de segmentación: la realidad manda y cuando estamos frente a los datos de un estudio tenemos variables de todo tipo. Desde variables nominales (sexo, conoce o no conoce mi marca, Comunidad Autónoma, etc.), variables ordinales (preferencias, escalas de acuerdo/desacuerdo, intención de compra, etc.), variables escalares y continuas (escalas de puntuación, miligramos, puntuaciones de escalas de calidad de vida, etc.).
Con estas variables tenemos que realizar una segmentación. La duda de siempre es cuál o cuáles de ellas elegir y la duda a veces no tiene fácil solución. Por una parte está el objetivo para el que se realiza la segmentación y por otro lado la limitación de las técnicas habituales que a veces no nos permiten utilizar variables del todo realistas.
Por poner un ejemplo, si utilizamos variables escalares o cuantitativas tenemos que utilizar un cluster del tipo K-medias, si tenemos que utilizar variables nominales nos vemos forzados a utilizar un cluster jerárquico. Muy probablemente la resolución del problema lo estamos limitando por la técnica y no porque tengamos claro que tenemos que emplear varios tipos de variables, nominales, continuas u ordinales.
Los nuevos algoritmos de Clases Latentes (no tan nuevos) nos permiten la flexibilidad de utilizar varios tipos de variables a la vez, tanto nominales, como ordinales o continuas, y por consiguiente no restarle realismo al problema y trabajar con las variables que nos van a resolver el problema y no sólo con aquellas que la tradición manda, léase K-medias o cluster jerárquico. Además las clases latentes eliminan la noción de "distancia" entre individuos para convertirla en algo más realista, como la probabilidad de un individuo de pertenecer a una clase o segmento en función de las variables utilizadas y no de inventar una medida de distancia.
Es, desde luego, una interesante aportación al mundo de la segmentación aunque también utilizada para la realización de análisis factoriales con variables nominales, incluso dicotómicas (no sólo de escalas) y regresiones agrupando individuos semejantes.
La realización de múltiples estudios con escalas de puntuación, likert, o similares. En la investigación de mercados es frecuente medir las preferencias, o la importancia de los ítems tales como marcas, características de productos, frases publicitarias, etc. La forma más común de medir estas cuestiones es con escalas de diferentes tipos. Las más usadas hacen referencia a:
1. La valoración con una escala de puntuación: por ejemplo valorar entre 0 y 10 puntos características tales como la potencia, los efectos secundarios, la toxicidad, etc.
2. Las escalas tipo Likert donde el entrevistado opina en una escala de acuerdo-desacuerdo para cada uno de los ítems (totalmente de acuerdo, de acuerdo en desacuerdo, totalmente en desacuerdo).
3. Ordenar las características o atributos, que sería disponer de un conjunto de características, por ejemplo, potencia, efectos secundarios, toxicidad, etc. y ordenarlos según el criterio que se proponga en el cuestionario. De esta forma el más preferido tendrá un valor de 1, el siguiente más preferido una puntuación de 2 y así sucesivamente.
4. Suma de puntos. Esta forma de medir se basa en que al entrevistado se le dan los atributos o características, por ejemplo potencia, efectos secundarios, toxicidad, etc. y se le pide que reparta 100 puntos entre los atributos con tal de estos puntos sumen 100 siempre, de esta forma cada uno de los atributos tendrá una valoración teóricamente diferente.
Hay otras formas de medir situaciones parecidas a las que hemos expuesto pero las anteriores son las más comunes.
Ningún tipo de medida de escala está exenta de problemas, pero apuntamos algunas de ellas.
La primera y la segunda forma de medir, las escalas de puntuación de 0 a 10 (pueden tener otro recorrido, por ej. De 1 a 5 o de 1 a 7) y las de Likert que pueden tener varios grados de acuerdo-desacuerdo, asumen que el entrevistado es capaz de reflejar en esas escalas su opinión y que la muestra entrevistada tiene el mismo parámetro de medida para poder contestar.
Dicho de otra forma, todos entienden lo mismo por una puntuación de 7 puntos, o todos entienden lo que es estar en descuerdo con la toxicidad de un fármaco. La tendencia, pues, a contestar a las escalas puede ser de diferentes maneras y con diferentes significados para cada puntuación produciéndose sesgos en las respuestas que no podemos controlar. Otro problema es la sobrevaloración de las cualidades positivas del ítem y la tendencia a puntuar por encima del valor promedio (en una escala de 0 a 10 puntos raramente alguien valora con un 2 o con un 3, la mayoría valora por encima de 5 o 6).
En ciertos mercados donde los colectivos son reducidos, como es el caso del sector farmacéutico, hay un fenómeno de aprendizaje que lleva al médico a valorar de forma similar muchos de los atributos que se le presenta, porque además ha participado en encuestas donde se le preguntan cosas de forma similar.
La ordenación de los ítems tiene dos principales inconvenientes, el primero es que la distancia entre cada uno de los ítems no tiene la misma unidad de medida, no sabemos cuánto es el tamaño del valor entre el primero y el segundo ítem ordenado y menos entre el tercero y el cuarto. Un segundo problema es que, si el número de ítems es importante el entrevistado pierde la noción de orden y le resulta difícil ordenar por ejemplo 15 atributos.
En la suma de puntos, generalmente 100, el principal inconveniente es el número de ítems, si estos son muchos el entrevistado pierde fácilmente el marco de referencia para contestar.
Actualmente existe el Método de Escalas de Máximas Diferencias que mejora ampliamente los problemas planteados con las escalas que hemos comentado. Se trata de preguntar al entrevistado de la siguiente forma:
¿CUÁL DE ESTAS FRASES ÉS LA MÁS IMPORTANTE YCUÁL LA MENOS IMPORTANTE PARA USTED?

A los entrevistados se les muestra un conjunto de combinaciones de ítems que pueden ser bloques de 3, 4 o más ítems y él/ella tiene que escoger entre el mejor y el peor o entre el más importante y el menos importante, etc.
Las combinaciones de ítems se diseñan de acuerdo con los principios del diseño experimental, con lo cual no hace falta que estén presentes todas las combinaciones posibles de pares o tríos de ítems, pudiendo estimarse un valor de importancia para cada uno de ellos.
Las principales ventajas de este método son las siguientes:
• Permite tratar a todos los ítems de forma igualmente importante o preferente.
• Fácil respuesta porque sólo consiste en elegir pares de respuestas, la mejor o la peor, la más importante o la menos, de un conjunto de ítems presentados.
• Reduce los sesgos que pueda presentar otro tipo de medida donde hay que decidir una posición numérica, de orden, etc.,
• Hay una fuerte discriminación en las respuestas y en los resultados numéricos.
• Es posible realizarlo en cualquier ámbito cultural y país con la consiguiente comparación de los resultados.
• Lo más importante para el tema que nos ocupa es lo siguiente:
- El resultado para cada ítem es en porcentaje.
- La suma de todos los ítems, como es lógico, es de 100% con lo cual su interpretación es muy sencilla: el ítem que haya obtenido % más elevados es más importante, valorado o preferido.
- Al entrevistado no se le pregunta por su valoración, sólo tiene que escoger tal y como ya hemos explicado.
- Los atributos, frases o ítems vienen ya ponderados y no hace falta dar un valor a cada ítem para especular sobre los más o menos importantes como sería el caso de las valoraciones de escalas.
- Los valores en tanto por ciento son para el total de la muestra y para cada entrevistado individual, con lo cual se puede segmentar la muestra en función de los valores resultantes teniendo segmentos de diferentes niveles de importancia o preferencia.
Esta forma de preguntar nos permite tratar a todos los ítems de forma igualmente importante o preferente, según sea la orientación de la pregunta.
El estudio de las preferencias y los estudios de pérdidas y ganancias de pacientes si variamos determinados atributos: las preferencias de los individuos son complicadas de medir y de relacionar con la conducta de compra o prescripción. No por ello debemos vernos derrotados en la posibilidad de medir algo tan útil como saber qué es lo que prefieren nuestros clientes, y si es posible llegar más allá en la cuantificación de posibles pérdidas o ganancias de pacientes si añadimos o variamos un atributo, que incluso puede ser un mensaje promocional.
Por ejemplo cuántos pacientes ganaríamos si hablamos de eficacia (concretando el significado de eficacia) en vez de o además de hablar de incrementar la rapidez de acción pasándola de una hora a 20 minutos. ¿Ganamos o perdemos pacientes?. Tenemos que elegir entre autopsia o biopsia. Dicho de otro modo, o hablamos de eficacia y un tiempo después medimos cuántos pacientes podemos haber ganado o perdido (sin saber claramente si ha sido debido a hablar de eficacia o a otros factores) o nos adelantamos al tiempo y simulamos unos escenarios en los que podemos preguntarnos, ¿qué pasaría si….? (what if?). Nos enfrentamos a hablar del presente-futurible (biopsia) o hablamos a toro pasado (autopsia) cuando probablemente la competencia ya nos ha hecho daño.
Nos estamos refiriendo al Conjoint Analysis.
Es una técnica de análisis de preferencias, en ella se manejan situaciones en las cuales un decisor tiene que ocuparse de opciones que simultáneamente varían a través de dos o más atributos. Mide los intercambios, para analizar las respuestas concernientes a las preferencias y a la intención de compra en las encuestas, y es un método para simular cómo nuestros clientes pueden reaccionar a los cambios en los productos actuales o en los nuevos, introducidos en una estructura competitiva.
El Conjoint Analysis concierne al día a día de las decisiones de nuestros clientes tales como:
• ¿Qué atributos son los más preferidos para mi producto?.
• ¿Soporta mi imagen unas ventas al menos similares a las actuales ante una eventual aparición de un genérico?.
• ¿A qué perfil de paciente debo ir?.
• Si tengo varios productos en mi porfolio. ¿a qué tipo de paciente voy con cada una de ellas?.
• ¿Cuántos pacientes puedo ganar o perder si varío un nivel de atributo?
• Análisis de preferencias: ¿qué prefieren y no prefieren (o prefieren menos) nuestros clientes?.
• Qué opciones de producto podemos añadir en una extensión de línea.
• Cómo podemos calcular nuestra canibalización en una extensión de línea, o qué porcentaje de clientes pueden preferir un nuevo producto de la competencia.
• ¿Cuál es la combinación más adecuada de producto y mensajes?.
• Segmentación de clientes por preferencias similares.
• Simulación de escenarios: la media total de las preferencias es poco útil para nuestros clientes en su toma de decisiones. Esta información puede simularse con diversos diseños de producto para saber qué tanto por ciento de nuestros clientes es más sensible a un diseño que a otro. Esta información es más manejable por los directivos para poder llegar a los target groups de sus productos. Es realmente lo más importante del Conjoint Analysis.
• Etc
Supongamos que tenemos un producto muy sencillo donde queremos conocer las preferencias de 4 atributos: marca, indicación, posología y forma de presentación y estos tendrán los siguientes niveles:

Tenemos 4x3x3x3=108 productos distintos que ofrecer a nuestro mercado, pero al diseñar un cuestionario no podemos preguntar por los 81 productos. Mediante la estadística (diseños experimentales y algoritmos de estimación) preguntamos sólo una fracción de los 108 productos posibles y luego podemos construir escenarios para conocer las preferencias de nuestros entrevistados. La forma de preguntar sería la siguiente:
SI ESTAS FUERAN SUS ÚNICAS OPCIONES, ¿CUÁL DE ELLAS PRESCRIBIRÍA?
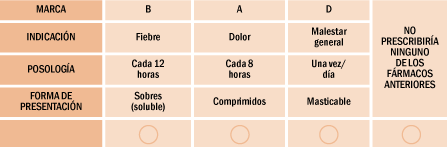
El entrevistado tendrá que elegir entre varias opciones como la que acabamos de presentar. Una vez hallados los resultados totales podemos construir escenarios de la siguiente manera:

Y preguntarnos qué % de médicos o componentes de la muestra prefieren cada uno de los productos que hemos diseñado. Un resultado (ficticio) podría ser el siguiente:
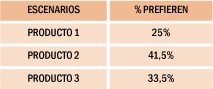
Podríamos hacer (más aún, debemos hacer) múltiples escenarios para conocer las diferentes variaciones que se pueden obtener al simular diversas composiciones de productos.
Quizás a estas alturas el lector se estará preguntado si estas preferencias pueden ser tomadas como previsiones de ventas. Claro que no, son sólo preferencias y si queremos extrapolar estas preferencias a ventas, unidades o euros, no nos cuadrarán las cuentas. Existe sin embargo una herramienta más novedosa que permite cambiar el sentido de las preferencias y ver las cosas en unidades, más concretamente en el campo farmacéutico hablaríamos de pacientes ganados o perdidos al simular escenarios como el ejemplo anterior. Vamos a tomar el mismo ejemplo anterior y presentar la misma definición del problema pero con pérdida o ganancia de pacientes:
POR FAVOR DR./DRA., ¿A CUÁNTOS PACIENTES PRESCRIBIRÍA CADA UNO DE LOS PRODUCTOS QUE FIGURAN A CONTINUACIÓN?

De esta forma las respuestas nos arrojarían pacientes y no % de preferencias. Por ejemplo, en el caso anterior del Producto 1, ese 25% de médicos que prefieren este producto, se podrían convertir en por ej. 2.500 pacientes y si la preferencia fuese del 40% los pacientes en cuestión serían 4.000.
Los mapas de percepción en los que se nos escapan las preferencias: dejamos este tema para un artículo posterior que os prometemos que será muy interesante.











